



GameBusiness.jpは、アマゾン ウェブ サービス ジャパン合同会社協賛の下、セミナー動画「“ゲーム開発×生成AI”最前線 知っておくべき最新動向と法知識」を公開しました。
セミナーでは立教大学大学院人工知能科学研究科特任教授の三宅陽一郎氏と弁護士法人STORIA法律事務所代表パートナー弁護士の柿沼太一氏が登壇。ゲーム開発における生成AIの最新研究事例や課題、知っておくべき知的財産権の知識などが講演されたほか、アマゾン ウェブ サービス(AWS)による生成AI関連サービスの紹介も行われました。
本稿では各登壇者のセッションと、三宅・柿沼両氏によるディスカッションの一部をご紹介します。本セミナー動画はオンラインで配信されています。視聴をご希望の方は、下記のリンクからお申し込みください。
動画の視聴はこちら40年以上の歴史を持つ「ゲーム開発と自動生成」
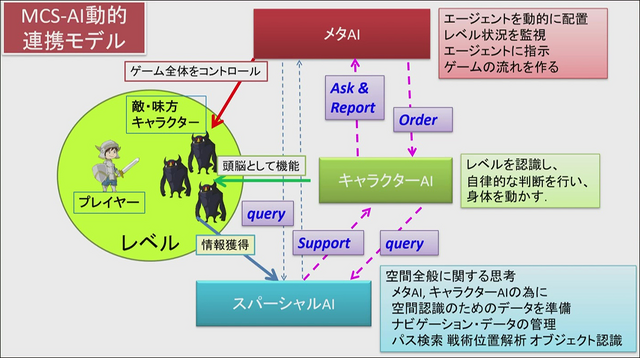
まずは三宅氏が登壇し、ゲーム開発現場におけるAIの歴史と生成AIの未来が語られました。ゲーム開発におけるAIは「ゲーム全体を制御するメタAI」、「キャラクターの頭脳となるキャラクターAI」、「空間全般に関する思考を行うスパーシャルAI」の3種類が存在し、このうちゲーム全体を司るメタAIが生成AIと関係するものだとしました。
三宅氏は、近年はゲームが大規模になってきており、人の手だけでゲームを作るのはもはや限界に来ていると指摘。今後のゲーム制作においては「人力+プロシージャル(自動生成)+適応型AI」を組み合わせて活用することが重要になっていくため、生成AIは避けては通れないと語りました。
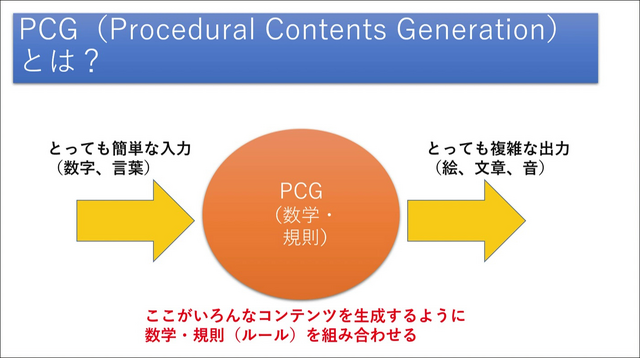
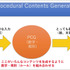
また、三宅氏は1980年の『Rogue』を例に挙げて、ゲーム業界では生成AIをゲーム開発に生かす動きが40年以上前からあったと紹介。そしてゲーム業界で長らく研鑽されてきたPCG(Procedural Contents Generation)にDNN(Deep Neural Network)が合わさることで、これからのゲーム開発がどのように変わっていくのかを解説しました。
さらに、講演では大手ゲーム企業やAI関連企業が生成AIとどのように向きあい、研究を進めているかの具体的な事例も多数紹介されています。
AWSにおける生成AI関連サービスを紹介
続いて、アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクトの大西啓太郎氏が登壇し、AWSの生成AIに関連するサービスを紹介しました。
AWSでは生成AIの技術スタックを「基盤モデルを活用するアプリケーション」、「基盤モデルを活用してアプリケーションを構築するツール群」、「基盤モデルの学習と推論のための基盤」の3つのレイヤーに分類して整理しており、それぞれのレイヤーにおける代表的なサービスが一つずつ紹介されました。
基盤モデルを活用するアプリケーション:Amazon Q
業務用に設計された、生成AIアシスタントです。ユーザーが所属する組織のさまざまな情報を参照して、会話ベースのやりとりで課題の解決策から必要なプログラムのコード生成まで、さまざまなソリューションを提案します。
基盤モデルを活用してアプリケーションを構築するツール群:Amazon Bedrock
APIを用いて生成AIアプリを簡単に構築・拡張できるサービスです。GDPR(General Data Protection Regulation/EU各国に適用される個人データ保護に関する法令)に適応するなどデータの安全性やプライバシーに配慮されており、本サービスで利用・生成したデータは、基盤モデルのトレーニングには使用されません。
基盤モデルの学習と推論のための基盤:AWS Inferentia / AWS Tranium, Amazon SageMaker
AWS Inferentia / AWS Trainium は、AWS独自の機械学習に特化した専用のシリコンチップで、モデルのトレーニングと推論の実行において、低コストに利用できます。
また、Amazon SageMaker はモデルの学習やデプロイに必要な一連のワークフローを効率化するサービスで、データの準備、特徴の抽出などを助けます。
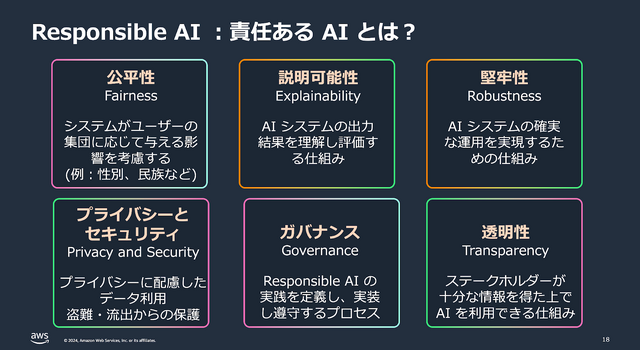
このほか、講演ではAWSが生成AIを使うことへの課題や取り組みをどのように認識し、具体的にどのような対策を行っているかが「Responsible AI/責任あるAI」というキーワードとともに解説されました。
生成AIをゲーム開発に利用する際の法的リスクは?
弁護士の柿沼氏からは、ゲーム開発に生成AIを利用する際の法的留意点が解説されました。
近年、生成AIの利用が法に触れていないかを確認する相談は増える一方で、生成AIの利用に関する問題は、利用場面ごとに以下の5つのパターンに集約されることが多いとしました。
他者の著作物をAIモデルの学習に使うことの是非
他者の著作物を学習には使わないが、入力/分析に使うことの是非
他者の著作物を入力/分析に使い、似たようなものを出力することの是非
他者の著作物を学習にも分析にも使っていないが、他者のデータと似たようなものを出力することの是非
他者のデータを学習に使い、似たようなものを生成することの是非
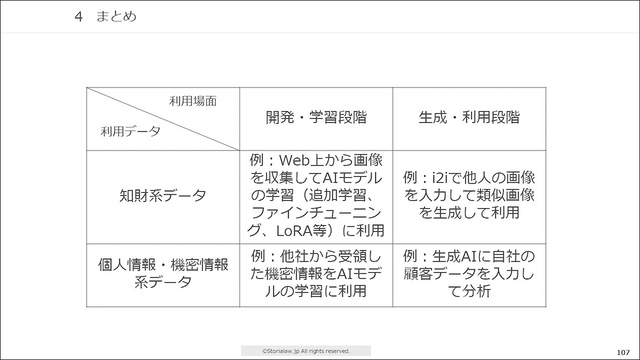
そして、これらのパターンを整理すると以下のようなフレームワークで分類できます。
知的財産権系データ × AIモデルの開発・学習段階
個人情報・機密情報 × AIモデルの開発・学習段階
知的財産権系データ × AI生成サービスの生成・利用段階
個人情報・機密情報 × AI生成サービスの生成・利用段階
講演では、上記の各パターンがそれぞれ合法か違法になりうるかが解説されたほか「自動生成AIの成果物(テキスト/画像/動画など)に作成者の著作権は生じるか」にも言及。法的なリスクのみならず、生成AIユーザーがどのような権利を持てるかにも迫っています。
三宅氏と柿沼氏によるディスカッション
最後に三宅氏と柿沼氏によるディスカッションが行われました。本稿では、多岐にわたる議題の中から「生成AIによる出力結果のコントローラビリティの特徴と課題」に関するトピックを抜粋・再構成して紹介します。
柿沼先ほどの講演では、ゲーム開発現場におけるPCGは40年ほど前から行われていたというお話でした。そこから現在までにさまざまな節目があったと思いますが、大きなターニングポイントはあったのでしょうか。
三宅2017年~18年頃を境に、それまではアルゴリズムをベースに生成していたものが、学習ベースに変わっていきました。それにより、何を学習したかでさまざまなデータが入ってくるようになりました。

柿沼そうなると、出力結果のコントロールがいい意味でも悪い意味でも難しくなりますよね。
三宅そうですね。アルゴリズムによる生成は、10個・20個程度のパラメータを調整すればさまざまなものを作れます。
何をどういじれば望むものを作れるかの尺度をコントローラビリティと呼んでいますが、機械学習による学習がベースとなった今は、コントロール可能な領域が非常に狭くなってしまいました。
一般に使う分には、予想だにしないものが生成されても「こんなものができてしまった」と楽しめばよいですが、クリエイティブの現場ではきちんと意図したものを作れる必要があります。
柿沼なるほど。生成AIで何を作るかによっても異なると思いますが、場合によっては法的なリスクもはらんだりしますよね。(ゲームに組み込むなどして)リアルタイムで何かを生成するのと、ゲームの開発中に制作現場で何かを生成するのとではどのような使い分けがされているのでしょうか。

三宅何が生成されるかコントロールしきれない以上、現状ではリアルタイムの生成は行いづらいと思います。テキストの生成であれば不適切な表現、3Dオブジェクトの生成であれば良く知られたオブジェクトなどが出てきてしまう可能性がありますから。もしそのようなことが起きた場合も、責任の所在すらはっきりしていないのが現状です。
その点、制作現場で活用する分には、世に出す前にきちんとチェックできるのが強みです。とはいえ、できるものなら(事前に)テキストを生成させるより、キャラクターにリアルタイムで自由に喋ってもらいたいわけです。そういうジレンマがありますね。
「AIにNPCのセリフをリアルタイムで話させる」というのは、今世界中のゲーム開発者が実現を目指しています。実際、インディーゲームではすでにそういうタイトルも存在します。しかし、コントローラビリティの狭さを考えると中規模、大規模なゲームではなかなか組み込みづらい事情があります。
GameBusiness.jpによるセミナー「“ゲーム開発×生成AI”最前線 知っておくべき最新動向と法知識」は動画配信されています。視聴をご希望の方は、下記のリンクからお申し込みください。
動画の視聴はこちらまた、アマゾン ウェブ サービスは6月20日(木)から21日(金)にかけて「AWS Summit Japan」を開催します。150を超えるセッション、250を超えるEXPOコンテンツを通してAWSに関する最新の知見や情報共有を行える参加無料のイベントで、生成AIに関するセッションも多数予定されています。詳細の確認や参加の登録は、AWS Summit Japanの公式サイトをご確認ください。